Let’s explore how to move from creating charts in Excel to generating them in R using AI assistance.
Where to start?
AI programs like ChatGPT allow you to paste data and charts directly into their interface and can provide you with a strong foundation for creating charts in R.
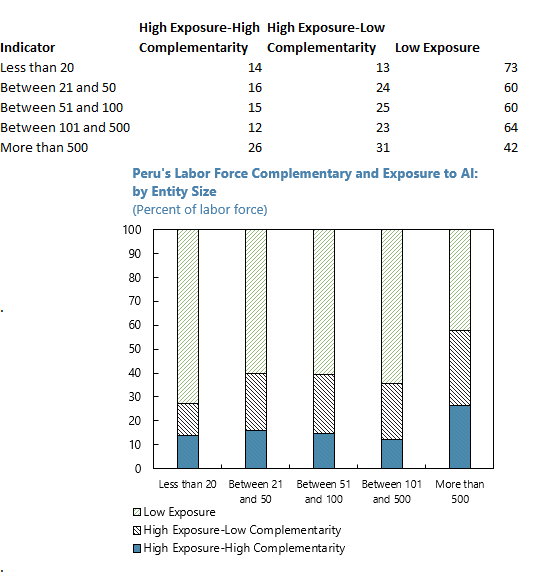
Let’s start with an Excel workbook that has a sheet containing our data and chart on it. Let’s use the example file titled “4.1.xlsx”, sheet, “AI_Entity_size”.
Copy the chart and the data and ask ChatGPT to write you a code in R to reproduce the chart.
The response you will receive will be something like the code below. You can run the code below and see that it produces a very similar chart.
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(tidyr)# Data (structured according to the image)data <-data.frame(EntitySize =c("Less than 20", "Between 21 and 50", "Between 51 and 100", "Between 101 and 500", "More than 500"),High_Exposure_High_Complementarity =c(14, 16, 15, 12, 26),High_Exposure_Low_Complementarity =c(13, 24, 25, 23, 31),Low_Exposure =c(73, 60, 60, 64, 42))# Reshape the data to long format for ggplotdata_long <- data %>%pivot_longer(cols =c(High_Exposure_High_Complementarity, High_Exposure_Low_Complementarity, Low_Exposure), names_to ="Exposure_Type", values_to ="Percentage")# Create the stacked bar chartggplot(data_long, aes(x = EntitySize, y = Percentage, fill = Exposure_Type)) +geom_bar(stat ="identity", position ="stack", color ="black", linewidth =0.3) +scale_fill_manual(values =c("#4B9CD3", "#88C1E9", "#D3D3D3"),labels =c("High Exposure-High Complementarity", "High Exposure-Low Complementarity", "Low Exposure")) +labs(title ="Peru's Labor Force Complementary and Exposure to AI: by Entity Size",subtitle ="(Percent of labor force)",x =NULL, y ="Percent") +theme_minimal() +theme(plot.title =element_text(hjust =0.5, size =14, face ="bold"),plot.subtitle =element_text(hjust =0.5, size =12),axis.text.x =element_text(angle =45, hjust =1),legend.position ="bottom",legend.title =element_blank() )
The beauty of AI tools like ChatGPT is that you can easily iterate on this. For example, let’s ask AI to ensure the title and subtitle are left adjusted, and that the X-axis labels are horizontal and ordered in the correct order.
Here you can see it quickly produces an adjusted code to do that.
# Load required packageslibrary(ggplot2)library(dplyr)library(tidyr)# Data (structured according to the image)data <-data.frame(EntitySize =c("Less than 20", "Between 21 and 50", "Between 51 and 100", "Between 101 and 500", "More than 500"),High_Exposure_High_Complementarity =c(14, 16, 15, 12, 26),High_Exposure_Low_Complementarity =c(13, 24, 25, 23, 31),Low_Exposure =c(73, 60, 60, 64, 42))# Define the correct order for EntitySizedata$EntitySize <-factor(data$EntitySize, levels =c("Less than 20", "Between 21 and 50", "Between 51 and 100", "Between 101 and 500", "More than 500"))# Reshape the data to long format for ggplotdata_long <- data %>%pivot_longer(cols =c(High_Exposure_High_Complementarity, High_Exposure_Low_Complementarity, Low_Exposure), names_to ="Exposure_Type", values_to ="Percentage")# Create the stacked bar chartggplot(data_long, aes(x = EntitySize, y = Percentage, fill = Exposure_Type)) +geom_bar(stat ="identity", position ="stack", color ="black", linewidth =0.3) +scale_fill_manual(values =c("#4B9CD3", "#88C1E9", "#D3D3D3"),labels =c("High Exposure-High Complementarity", "High Exposure-Low Complementarity", "Low Exposure")) +labs(title ="Peru's Labor Force Complementary and Exposure to AI: by Entity Size",subtitle ="(Percent of labor force)",x =NULL, y ="Percent") +theme_minimal() +theme(plot.title =element_text(hjust =0, size =14, face ="bold"), # Left-align titleplot.subtitle =element_text(hjust =0, size =12), # Left-align subtitleaxis.text.x =element_text(angle =0, hjust =0.5), # Horizontal X-axis labelslegend.position ="bottom",legend.title =element_blank() )
Now that you have built the foundation, let’s move on to connecting our excel files directly.
Reading Excel Files
We can ask AI to help us read this data directly from our Excel file. It is critical, however, to set up our data correctly in Excel before importing it in R. We want the data in a format that R can easily read and process.
Structuring Your Data in Excel
Our example, for this exercise is structured correctly, with clear headers and easy interpretation. However, it is best practice to put it in its own sheet. Let’s create a sheet in Excel workbook “4.1”, and call it “Chart 4 Data”, that includes only the relevant data.
In general, here are some best practices for your Excel workbooks for reference:
Headers: The first row should contain headers that clearly describe the data columns. For example, “Country,” “Indicator”.
Consistent Data Types: Ensure that each column contains consistent data types (e.g., all numbers, all text).
No Merged Cells: Avoid merged cells as they can cause issues during data import into R.
Importing our Data
Let’s now ask ChatGPT to help us read this data from our Excel file instead. Make sure to specify the location of the file and the name.
It will produce a code similar to this one for you to copy and run in your R console.
# Define the path to the Excel file using the `here()` functionfile_path <-here("databases", "4.1.xlsx")# Read data from the specified sheet in the Excel filedata <-read_excel(file_path, sheet ="AI_Entity_size")# Check the column names of the data to ensure correct assignment# print(colnames(data))# Assuming the data has similar column names to the previous example# You can adjust the column names based on your actual data structure if neededcolnames(data) <-c("EntitySize", "High_Exposure_High_Complementarity", "High_Exposure_Low_Complementarity", "Low_Exposure")# Reshape the data to long format for ggplotdata_long <- data %>%pivot_longer(cols =c(High_Exposure_High_Complementarity, High_Exposure_Low_Complementarity, Low_Exposure), names_to ="Exposure_Type", values_to ="Percentage")# Create the stacked bar chartggplot(data_long, aes(x = EntitySize, y = Percentage, fill = Exposure_Type)) +geom_bar(stat ="identity", position ="stack", color ="black", linewidth =0.3) +scale_fill_manual(values =c("#4B9CD3", "#88C1E9", "#D3D3D3"),labels =c("High Exposure-High Complementarity", "High Exposure-Low Complementarity", "Low Exposure")) +labs(title ="Peru's Labor Force Complementary and Exposure to AI: by Entity Size",subtitle ="(Percent of labor force)",x =NULL, y ="Percent") +theme_minimal() +theme(plot.title =element_text(hjust =0, size =14, face ="bold"), # Left-align titleplot.subtitle =element_text(hjust =0, size =12), # Left-align subtitleaxis.text.x =element_text(angle =0, hjust =0.5), # Horizontal X-axis labelslegend.position ="bottom",legend.title =element_blank() )
We can see it is a bit different from the previous example. Let’s ask AI to help us remove the grid lines, wrap the X axis labels, and order the X axis correctly.
# Load required packageslibrary(readxl)library(ggplot2)library(dplyr)library(tidyr)library(here)library(stringr)# Define the path to the Excel file using the `here()` functionfile_path <-here("databases", "4.1.xlsx")# Read data from the specified sheet in the Excel filedata <-read_excel(file_path, sheet ="Chart 4 Data")# Remove rows where the 'Indicator' column is NAdata <- data %>%filter(!is.na(Indicator))# Map the Indicator values to the new desired x-axis labelsindicator_labels <-c("Less than 20","Between 21 and 50","Between 51 and 100","Between 101 and 500","More than 500")# Assign the new labels to the Indicator column and wrap the labelsdata$Indicator <-factor(data$Indicator, levels =unique(data$Indicator), labels =str_wrap(indicator_labels, width =10))# Reshape the data to long format for ggplotdata_long <- data %>%pivot_longer(cols =c(`High Exposure-High Complementarity`, `High Exposure-Low Complementarity`, `Low Exposure`), names_to ="Exposure_Type", values_to ="Percentage")# Create the stacked bar chartggplot(data_long, aes(x = Indicator, y = Percentage, fill = Exposure_Type)) +geom_bar(stat ="identity", position ="stack", color ="black", linewidth =0.3) +scale_fill_manual(values =c("#4B9CD3", "#88C1E9", "#D3D3D3"),labels =c("High Exposure-High Complementarity", "High Exposure-Low Complementarity", "Low Exposure")) +labs(title ="Peru's Labor Force Complementary and Exposure to AI: by Entity Size",subtitle ="(Percent of labor force)",x =NULL, y ="Percent") +theme_minimal() +theme(plot.title =element_text(hjust =0, size =14, face ="bold"), # Left-align titleplot.subtitle =element_text(hjust =0, size =12), # Left-align subtitleaxis.text.x =element_text(angle =0, hjust =0.5), # Horizontal X-axis labelspanel.grid.major =element_blank(), # Remove major gridlinespanel.grid.minor =element_blank(), # Remove minor gridlineslegend.position ="bottom",legend.title =element_blank() )
IMF Format
While this looks good, it is not in IMF format. Let’s now adjust the code so that we use IMF format and name the figures so that we can refer to them more easily.
We know from previous sections in the book that we can load the IMF format from our source packages. Let’s ask ChatGPT to help us load and use them.
Your code will now look something like this.
# Load required packageslibrary(readxl)library(ggplot2)library(dplyr)library(tidyr)library(here)library(stringr)# Source IMF theme and custom text functionsource(here("utils/theme_and_colors_IMF.R"))source(here("utils/Add_text_to_figure_panel.R"))
Attaching package: 'gridExtra'
The following object is masked from 'package:dplyr':
combine
# Define the path to the Excel file using the `here()` functionfile_path <-here("databases", "4.1.xlsx")# Read data from the specified sheet in the Excel filedata <-read_excel(file_path, sheet ="Chart 4 Data")# Remove rows where the 'Indicator' column is NAdata <- data %>%filter(!is.na(Indicator))# Define new labels for the Indicator columnindicator_labels <-c("Less than 20","Between 21 and 50","Between 51 and 100","Between 101 and 500","More than 500")# Assign the new labels to the Indicator column and apply word wrappingdata$Indicator <-factor(data$Indicator, levels =unique(data$Indicator), labels =str_wrap(indicator_labels, width =10))# Reshape the data to long format for ggplotdata_long <- data %>%pivot_longer(cols =c(`High Exposure-High Complementarity`, `High Exposure-Low Complementarity`, `Low Exposure`), names_to ="Category", values_to ="Value")# Create the stacked bar chart with IMF themefig1 <-ggplot(data_long, aes(x = Indicator, y = Value, fill = Category)) +geom_bar(stat ="identity", position ="stack") +labs(title ="Peru's Labor Force Complementary and Exposure to AI: by Entity Size", # Add your title heresubtitle ="(Percent of labor force)", # Added subtitle for clarityx ="", # Removing X axis labely =""# Removing Y axis label ) +theme_imf() +# Apply the custom IMF themetheme(plot.title =element_text(hjust =0, size =16), # Left-align and set title sizeplot.subtitle =element_text(hjust =0, size =12), # Left-align and set subtitle sizelegend.position ="bottom", # Position the legend at the bottomlegend.direction ="horizontal", # Arrange legend items horizontallylegend.title =element_blank(), # Remove legend titlelegend.background =element_blank(), # Remove legend backgroundlegend.text =element_text(size =9), # Set legend text sizelegend.key.size =unit(0.5, "cm"), # Set size of legend keyslegend.margin =margin(t =0, unit ="cm") # Adjust margin around legend ) +scale_fill_manual(values =c("High Exposure-High Complementarity"="#96BA79","High Exposure-Low Complementarity"="#A6A8AC","Low Exposure"="#4B82AD")) # Apply IMF color scheme# Display the plotprint(fig1)
Lastly, we can ask AI to make improvements to the chart while maintaining the IMF theme, and clean up the code for our finalized chart. We can see that it now has placed the title across two lines for enhanced visibility, added bar aesthetics, and some font size adjustments.
# Load required packageslibrary(readxl)library(ggplot2)library(dplyr)library(tidyr)library(here)library(stringr)# Source IMF theme and custom text functionsource(here("utils/theme_and_colors_IMF.R"))source(here("utils/Add_text_to_figure_panel.R"))# Define the path to the Excel file using the here() functionfile_path <-here("databases", "4.1.xlsx")# Read data from the specified sheet in the Excel filedata <-read_excel(file_path, sheet ="Chart 4 Data")# Remove rows where the 'Indicator' column is NAdata <- data %>%filter(!is.na(Indicator))# Define new labels for the Indicator columnindicator_labels <-c("Less than 20","Between 21 and 50","Between 51 and 100","Between 101 and 500","More than 500")# Assign the new labels to the Indicator column and apply word wrappingdata$Indicator <-factor(data$Indicator, levels =unique(data$Indicator), labels =str_wrap(indicator_labels, width =10))# Reshape the data to long format for ggplotdata_long <- data %>%pivot_longer(cols =c(`High Exposure-High Complementarity`, `High Exposure-Low Complementarity`, `Low Exposure`), names_to ="Category", values_to ="Value")# Create the improved stacked bar chart with IMF themefig1 <-ggplot(data_long, aes(x = Indicator, y = Value, fill = Category)) +geom_bar(stat ="identity", position ="stack", color ="black", size =0.25) +# Thinner border labs(title ="Peru's Labor Force Complementary and Exposure to AI:\nby Entity Size", # Left-align title and new line for "by Entity Size"subtitle ="(Percent of labor force)", # Left-align subtitlex ="Entity Size", # Adding X axis labely ="Percent of Labor Force"# Adding Y axis label ) +theme_imf() +# Apply the custom IMF themetheme(plot.title =element_text(hjust =0, size =16, face ="bold"), # Left-align title and adjust sizeplot.subtitle =element_text(hjust =0, size =12), # Left-align subtitleaxis.title.x =element_text(size =10), # Reduce X axis label sizeaxis.title.y =element_text(size =10), # Reduce Y axis label sizeaxis.text.x =element_text(angle =0, hjust =0.5, size =8), # Adjust x-axis text sizeaxis.text.y =element_text(size =8), # Adjust y-axis text sizelegend.position ="bottom", # Keep legend at bottomlegend.direction ="horizontal", # Horizontal legend itemslegend.title =element_blank(), # Remove legend titlelegend.background =element_blank(), # Keep legend background blanklegend.text =element_text(size =8), # Adjust legend text sizelegend.key.size =unit(0.6, "cm"), # Slightly increase legend key size for better visibilitylegend.margin =margin(t =5), # Adjust margin around legendpanel.grid.minor =element_blank() # Remove minor gridlines for cleaner look ) +scale_fill_manual(values =c("High Exposure-High Complementarity"="#96BA79","High Exposure-Low Complementarity"="#A6A8AC","Low Exposure"="#4B82AD")) # Apply IMF color scheme# Display the plotprint(fig1)
You’ve now seen the basics of using AI tools like ChatGPT to help transition your Excel charts to R charts.